在2017网络安全生态峰会上,观数科技CEO李科分享了政企单位应该如何保证大数据生态组件的安全,在一直播搜索「观数科技」即可查看录播。
以下是文字实录,阅读时长15分钟。

(请宽容对待此图,怪我们像素太渣,老板说把他拍成了丁丁历险记)
大家好,我是李科,观数科技是一家为客户提供大数据平台底层保护能力的安全厂商。今天给大家分享的内容是,如何保护大数据生态组件的安全,大致分为四个部分:
-
大数据安全面临的挑战
-
大数据平台的威胁
-
目前的有哪些解决办法
-
大数据安全方案
一、大数据安全面临哪些挑战
熟悉大数据的应该都知道,目前所谓的大数据生态组件,比较常见的就是Hadoop。
这个组件不是一个软件,是一系列的生态组件。现在的列式数据库、机器学习,还有其他各种各样的应用越来越多,它的组件生态越来越复杂。
问题来自两个方面,一方面是平台自身确实包含了一些漏洞,另一方面是大数据组件本身提供的一些功能,也可能会诱发一些隐患。
这些隐患主要来源于三个方面:
第一个是基于安全配制,我们经常用的Apache的发行版,或是CDH、HDP,安全配置并不是默认全开了的。
第二个是安全性上比较脆弱。我们知道2006年Hadoop从谷歌开源出来,并没有没有考虑安全性的问题。后来版本不断迭代,很多厂商才为它提供了安全的功能。
第三个由于采用分布式的架构,这和数据库原来集中式的架构是有很大区别的,它的复杂结构也带来一系列的安全问题。

今年大家关注最多的,可能就是勒索攻击了。其实针对Hadoop这种勒索工具在今年1月份已经产生了。
当时MongoDB这种开源的产品,都遭受过勒索攻击。我们在1月份推出过针对Hadoop抵御勒索攻击的免费补丁,有兴趣的话大家可以去我们的官网看看。
为了给大家更清晰的展示,我们做了一个测试环境,在两台客户机上建立自己的用户名,分别叫User1、User2。
张三的计算机上有一个用户叫张三,另外一台上也有叫张三,这两台一样吗?肯定是不一样的。因为这是两台计算机上用户名相同的不同用户。
在这种情况做测试,我们看看大数据平台都面临哪些威胁。
二、大数据平台的威胁
1.用户冒充攻击
介绍两个配制文件。第一个是在Hadoop HDFS里,这个里面有Hadoop相关的权限开关,如果你使用Simple模式,你没有任何的权限。

第二个是Hdfs—site.xml文件里有一个dfs.permissions.enabled,开启或关闭均可。
上传一个文件,比如说修改文件的属性,这样的话你在客户机上用同样的User,就可以访问集群中的任何文件。
大家知道刚才说的User1,User2只是操作系统的用户名,真正的Hadoop当前用户名是不需要密码的,所以这个普通用户攻击冒充攻击这样就可以很轻松的完成了。

同理Hbase是非关系性数据库,除了dfs.permissions.enabled,哪怕是Hdfs—site关闭和开启都能影响hdfs。
2.普通用户的越权访问
这种情况在你的Sdfs里不管是用Simple还是Kerberos模式,在Windows 3T里面在用了。


如果把dfs.permissions.enabled关闭,在客户机上登入User2,权限为700的操作者是可以打开User1的文件的。
因为什么?虽然你校验了用户,但是没有校验权限,用户不同,没有对比权限,授权关闭的话,不同的用户访问其他的文件。
3.特权用户越权访问
如果Hadoop是root起的,不管是哪个用户建的表,只要用root,或者是启用Hadoop用户访问其他用户的表都是可以的。


4.暴力破解
相对来说比我们破解SSH登陆的简单的多,破解SSH破解的是用户的密码,主机上尝试多次以后拒绝连接。
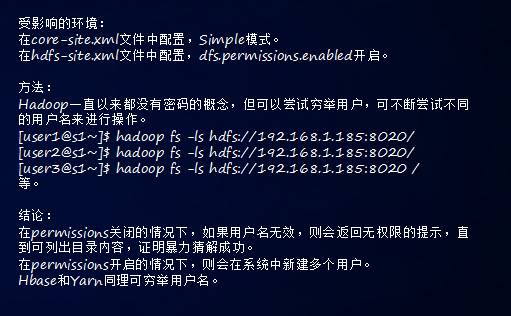
但是在Hadoop需要尝试的只是你的用户名,当你的用户名对比成功的时候,其实不需要密码,可以把里面的目录列出来。
所以在dfs.permissions.enabled关闭的情况下,用户名无效,就会有返回权限的提示,直到可以列出目录来,他可以暴力破解你的用户名就可以了。
5.嗅探攻击、Datanode直接访问风险
相信大家都用过Hadoop,比如说50070端口开启的时候看到Datanode页面的,可以看到Block ID。
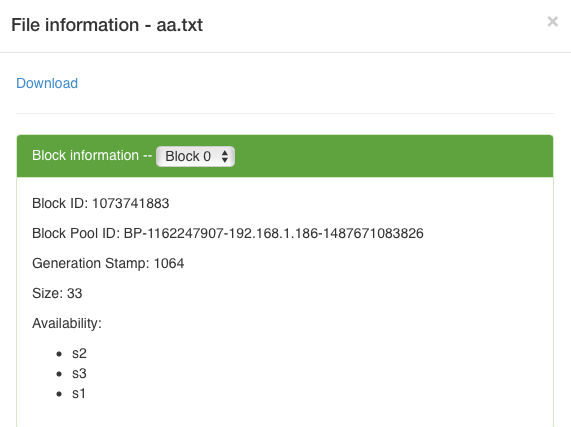
通过网络抓包可以把上传或者是下载一个aa.txt,这是获得Block ID的一个方法。
6.物理攻击-掏磁盘
所谓的物理攻击有两种,第一种就是我直接去掏人家的磁盘。

接触到磁盘的时候做一个测试,比如说我们写一个date.txt文件,随便敲一个字符,传输到集群里的时候,发现Hadoop集群里多了一个文件,这个文件实际上就是刚才data.txt点击生成的文件。
直接可以看到名文,这说明什么?说明我们的文件在意传到datanode的时候,是没有经过任何处理的。这种情况下如果我们能够接触到大数据的集群就可以做物理攻击。
7.物理接触攻击-冒充Datanode
两个Datanode以前可能带了一百台Datanode节点,把其中一个datanode节点网线拔下来,把这个笔记本装了这个Datanode相应的程序,并且读取了证书,可以用笔记本去接触,更强大容错和恢复机制导致的,只要发现有新的Datanode就把自己的数据往那个地方去复制。

攻击者可以很轻松的把这一部分数据拿走,而且大家还不知道,拿走以后可以把网线插进去。
还有一种可以远程去攻击的,主要是利用Mapreduce的框架。
Datanode一部分是分布式文件系统,还有一部分是Mapreduce分布是计算框架,我们写完架包上传,上传到任何一个节点上,用Mapreduce执行,任何节点有可能访问全部的数据,架包里面可以调动集群里面任意的数据。
我们看一下比如说这个希望例子,Hadoop里面有很多参数,这样里面有Mapper和reducer,执行这指令的时候我们可以读到文件配制,这个非常危险。
接下来我相信大家都用过这个工具MSF,这是很多渗透测试的时候用了一个开元框架,用这个工具百度可以下载到,你们如果是有兴趣可以自己试一下。

生成一个MSF反联程序,到外面指定的技术和端口,这是标准的MSF底下的,任何MSF上都可以用。
我们生成这个文件以后,我们设置好IP地址等等,之后利用Hadoop这个工具,把这个文件传上去,用Mapper执行它。起动MSF框架,生成一个文件,监听连接端口。
三、目前的有哪些解决办法
我们自己做了一套BIG RADAR全球大数据探测雷达,在互联网上一周的时间,这是我们7月份在数博会上的一个展示,发现有5.7亿个文件,17PB的数据,都是可以被勒索攻击的。
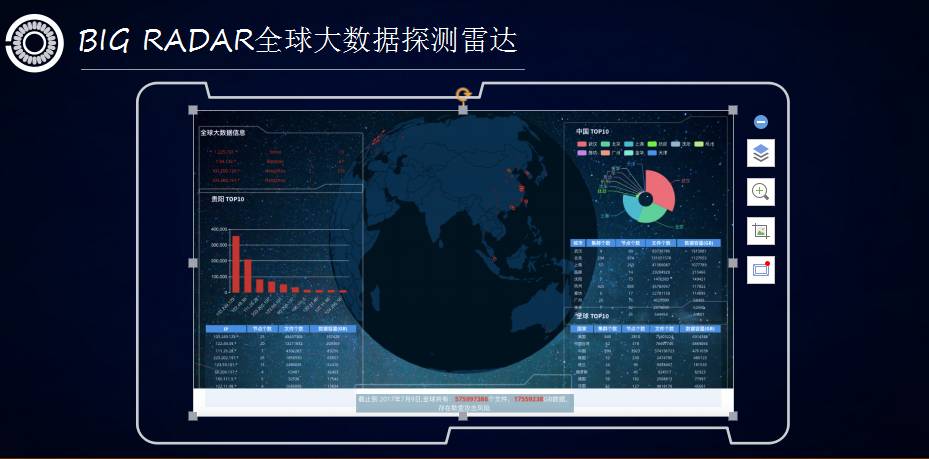
这是我们在互联网上探测到的风险数据,我相信内网当中的风险数据要比这个多N倍。那是不是说现在的Hadoop就非常不安全?

其实Hadoop比起安全组件,在认证授权这块,主要采用的是Kerberos加ldap;
在透明加解密上有KMS上可以使用;
节点间通信有SSL组件去进行加密;
日志审计Hadoop有自己的基于log4j的形式文件产生,会存放在意本地目录。
这是Hadoop里面已经具备的功能,但是这些开源组件的开放程度很低,少有人用,也少有人会用。
四、我们在大数据安全领域的解决方案
我们认为,企业对大数据的安全需求主要有四块。

第一个是合规性。合规性分两个层面,第一个层面是法律法规的合规。大家都听说过等级保护,以前等级保护是一个指导性的文件。但是今年以后已经成为法律,就是信息系统上线以后,必须要走等级保护那一套体系,必须要满足等保的测评。
其次是业务层面的合规,必须要具备帐户授权认证审计,这一套4A的体系,如果不具备的话那你连基础上线的条件都不具备。实际上现在Hadoop分布式组件这种4A的特性是不满足现在需求的。
第二个是数据治理的需求。这包括三个方面,角色化、任务化、属性化。
1.角色化。大家可能都听说过基于角色访问控制,数据堆积到一起,发挥价值的时候,需要进行角色区分。
做征信的分析师,访问征信的数据是合理的。但是做征信去访问人脸识别的数据,实际上业务没有这个需求的,而且也是不合规的。
所以用角色化把我们主课题区分开,比较实施访问控制策略是企业一个需求。
2.任务化。在自动化生产的过程中,我们需要把我们的任务在启动的时候赋予它主课题的权限,任务结束以后把这个权限收回来。
3.属性化。基于属性的访问控制。任何数据都有自己的属性,可能是机密性的属性,可能是完整性的属性,这些随着我们数据在整个大生命周期里只是访问控制的策略。
第三个是安全事件。Hadoop组件可能产生大量的日志,这些日志对企业来说没有太多的价值,因为没有人那么多时间去分析,企业最关心的是:
这些日志发现什么问题?什么是时候发生了什么样的攻击?我受到什么样的损失?这是企业比较关心的。所以怎样从日志里面提出安全事件是企业比较关心的问题。
第四个是敏感数据。在今年7月1号实施《网络安全法》里面规定了数据的责任保护单位,比如说个人隐私,数据发生泄露这些使用数据单位要负责的。
这就涉及到数据的透明加解密的需求,涉及到数据脱敏的需求。对于敏感数据的脱敏,密钥是必不可少的。
这是我们总结四个企业大数据安全需求。现有的常见的保护思路,给大家介绍一下。主要是这三种思想:

第一种叫边界,我们叫护城河模式,这是最简单的,也就是说我们先把Hadoop建好以后放在内网里面。
在这种情况下,外网不能直接访问,风险来源降低了,也不会有什么系统损耗。
但是也带来一定的弊端,第一个是无法提供服务,数据无法直接交换;另外内网完全没有防控能力。
勒索工具感染大部分地方都是在内网。当你和互联网脱离以后,你的桌面安全防护,包括你的网关都很难及时做到更新,所以内网没有任何防护能力。
第二种基于架构的安全防护思路。采用SSL加密,采用kerberos做凭证服务,实现组件和客户端之间的身份认证。
它的优势是无须部署边界,对外提供服务。但是它的问题是部署和运维成本高。
我们知道kerberos你集成上规模的时候,你集群增加节点,你需要重新去调整kerberos,看到很多用户出现问题,都是因为这个。
第三个就是以数据为核心的保护思路。具体来说就是对数据进行标记化处理,脱敏加密,解决的是数据共享的问题。但是坏处就是有明显的性能损耗。
以上是三种常见的保护思路,我们观数科技研发的一套产品—BIG DAF,实际上是上面三个思路的一个结合体。
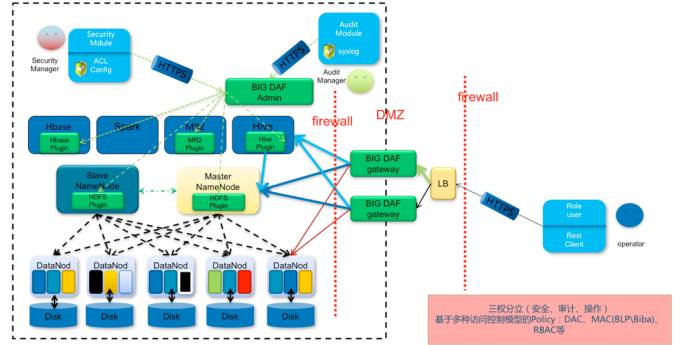
我们在边界的基础上增加了两个BIG DAF,Gatewa起到代理的作用,进行组件的时候需要在Gateway身份认证。
这个组件是一个后台,通过访问控制模型,配制完以后会分发到各组件产品第三步,部署在每一个应用的节点上,把下发的安全规则进行落地。
哪个可以访问,哪个用户可以访问哪个文件plugin;审计官员只能看日志,不能配安全规则,也不能通数据;操作人员通过Gateway进行访问,既有边界又有访问策略。
这种架构在内网当中对性能没有任何损耗,因为我们没有在中间停串什么东西,没有解决流量或者是转发的问题。所以所起到的作用就是对资源的访问权限管理。
在今年的贵阳的数博会上,国务院马凯副总理对我们这套完全自主知识产权的产品,给予了高度的肯定。

去年在贵阳网络安全攻防演练里边,一百多个网络安全高手对这个产品进行攻击测试,三天时间,没有任何损耗,所以它的强壮度还是比较高。
目前BIG DAF也是国内唯一一个拿到公安部三所检测认证的基于Hadoop的安全防护产品。
分享就到这里,大家有什么问题,可以私底下随时沟通,谢谢大家。